In order to store or use a revision, monotone currently requires the complete ancestry of the revision to also be in the local database. Whenever a revision is sent as part of a pull, all of its ancestors are sent too if they're not already at the receiver.
This ensures that the entire history can be completely validated, and ensures the history can never be lost. It can also make the initial pull of a large project take a long time, and result in a large database containing much historical information that users may not want or need.
Some users just want to track a project and some recent history: perhaps the current release branch for important fixes.
We use the term Partial Pull to refer to possible future implementations that would allow revisions to be sent and used, disconnected from parts of their history.
Implementation details
Missing revisions are represented by a horizon. The horizon is generated from the initial partial pull request and stored as a list of nodes which are the first (most recent) ones missing. See table
sentinelsFor the initial partial pull we need an additional option to send to the other host which indicates that only a subset of the revisions are going to get synchronized. For subsequent synchronizations you would have to tell the other side about the horizon. Using this information both sides can construct a decent merkle tree for synchronization.
we need to change database storage, internal roster storage, netsync, db check and many user interface commands.
Plan to implement it
Table with horizon/fake nodes will be called sentinels (unique
indexed set). You have to test for members of this set as well as for
the empty revision.
See the following graph ( ):
):
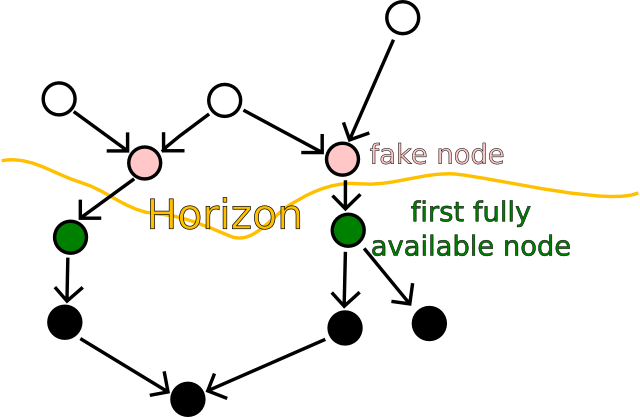
Light red nodes form the horizon (are stored in sentinels), dark
green nodes have additional information in horizon_manifests to
create rosters for them.
Store Manifest and File ID information for the first fully available nodes in a new table (
horizon_manifests)update database code: add tables, make possible to create - put_parentless_revision etc. regen_rosters <= start here
define the manifest+id format
netsync needs to generate; server & client need extending; knowing how to choose a horizon, transmit a horizon, move a horizon
need UI for this
need all other commands to not crash on such databases, review every command
- sugar (db info, etc)
Open questions
- How to display incomplete revsions in log? IMHO we should call it "unknown" or "partial" or "yet unknown" or "not present".
More comments from njs
The important question is what exactly the horizon looks like. Here's a graph:
A B C
\ / \ /
--------------------- horizon
\ / \ D
E \ /
F
Important facts:
For purposes of netsync, we have all versions that are descendents of the set: D E.
I assume that "we have" means at least, we have the files and rosters for D, E, F, but not A, B, C. D, E, F are exactly the first revisions that 'checkout' can succeed for.
For initial netsync, and later regenerate_caches (i.e., migrations), we need to receive and store a map. This really should be thought of as a single structure, since these local ids are different from our local node_id's -- these ids are only valid for comparison with other ids in other manifests in this single map.
A question is which revisions we should receive/store manifests+ids for. The answer is, "the first revisions that we want to have rosters for", i.e., E D F (note that this is different from the D E set that specifies everything we need to fetch above... the difference is between "we have all descendents of this" versus "we are missing at least one parent of this". This is kind of an annoying difference, and we should think about it more, probably). The reason this is the answer is that firstly, we need this to construct rosters at all, and secondly, there is utterly no point in having any more than this -- we could get it a little higher up, like we could send the A B C manifest+ids, but then we'd just have to turn htem into rosters in memory to create the E D F rosters, but then not write the A B C rosters to disk... pointlessness.
- Also, for lots of algorithms, we need to know "is this parent rid that I'm looking at a 'root' (horizon) revision?". Because if it is, we should stop traversing the revision graph, rather than fetch something and die. (Right now the only parent rid that we stop at is the magic id [], but this increases the size of that sentinel set.)
So we know exactly which revisions have files, rosters, and funky-partial-pull-manifest-things saved. The only questions left are what revisions we fetch/store revisions for, and which revisions we fetch/store certs for.
For certs, we can do pretty much anything we want -- but probably the right thing to do is just to have certs for E D F and descendents, but not otherwise. This means that e.g. selector-based checkout can work for E D F.
So, that just leaves revision texts, which are the point of contention. Now, it turns out that the only thing you need a revision text for is generating a roster for that revid. So that means that we need revision texts for all the descendents of E D F, but in fact we don't need the revision text for E D F -- because we generate their rosters directly from the fake manifest thingie. We can store it, but it's not required. I think that we could do that, but it will simplify the code, and reasoning about it, if we just go ahead and store these unnecessary revisions. With this approach, there are only two states a revision can be in: "we have everything", and "we have nothing".
We need to be able to quickly locate all manifest+id structures, because whenever we move our horizon (which can happen on any pull), we need to delete all of them as a unit, and replace them with the new ones being sent. (NB this is true even if some nodes on the old horizon are also on the new horizon -- because we need a consistent local id set and we can't get that otherwise!) All that seems to suggest that storing them in a lookaside table is the simplest approach...